RabbitMQ vs Kafka
So you need a message broker and are unsure about which one. In this article, I will try to explain what are the technical differences.
tl;dr They belong to different categories of messaging infrastructures, and their feature set is respectively different. RabbitMQ is a message broker, but Apache Kafka is an event streaming platform. So if you need some features available only in one broker, choose that one. Kafka is more complex by design (you better understand it), and it comes with an entire platform for event processing (i.e. for real-time data processing). So if you don’t do any stream processing and only need a broker for message delivery (e.g. for service decoupling), just choose RabbitMQ because of its simplicity. Kafka is the way to go for stream processing.
Broker features
First of all a few vocabulary differences to be able to start off the discussion. Brokers have to store its messages somewhere. RabbitMQ uses the term of queue for that place, and Kafka the term of topic. So a RabbitMQ Queue is similar to a Kafka Topic and it is the place where messages are stored and from where consumers read them.
Message ordering
Message ordering in distributed systems is generally a difficult problem (simply imagine you have multiple consumers and producers). But you might anyway expect from the broker perspective that messages get stored in their publication order. This is true for RabbitMQ, but for Kafka, this is generally not true. Kafka does not guarantee message ordering across partitions (which compose a topic), but only within each partition. So, in Kafka, to find a working solution to your specific ordering problem you have to deal from the very beginning with so-called partitioning. Attention is also required during operation (for instance, when updating the partitioning strategy or when changing the number of partitions in a topic).
Message lifetime after consumption
In RabbitMQ messages are deleted on consumption from the queue, but in Kafka they remain persisted according to a retention policy. This could be useful in many scenarios, like when you detect some problems on the consumer side and want to replay all messages newer than a certain time. In RabbitMQ you have to implement your own replay strategies.
Priority queue
RabbitMQ supports priority queues out of the box, but Kafka doesn’t.
Priority queues are good when producers set the order in which messages should be consumed (based on data other than message timestamp). For instance, producers send data about patient arrival at a hospital and you want consumers to handle it according to patient severity.
There are use cases of the prioritization problem when you can split the priorities into buckets. For these, there are technical solutions in Kafka, but they increase the system complexity and implementation effort compared with RabbitMQ.
Message expiration
Both brokers support message expiration on the queue/topic level. But only RabbitMQ supports it on the per-message basis.
In Kafka you could set the timestamp field in the message to a value depending on the topic retention time, but this is
error-prone because topic retention can change without changes in producer code.
Message compaction
Kafka has a feature called message compaction which is useful when consumers are interested only in the last message with the same key. Imagine the messages are updates of user profiles, so you care only about the last profile update of any user. RabbitMQ has no such feature, and you’ll have to implement this in another data store.
Schema support
Although separated from the broker, Kafka comes with an (optional) schema registry where you can store versioned schemas for your topics. And messages can be validated on publishing and consumption. Also, you can enforce compatibility restrictions on schema updates. RabbitMQ offers unfortunately no help here.
Technical differences
Message path
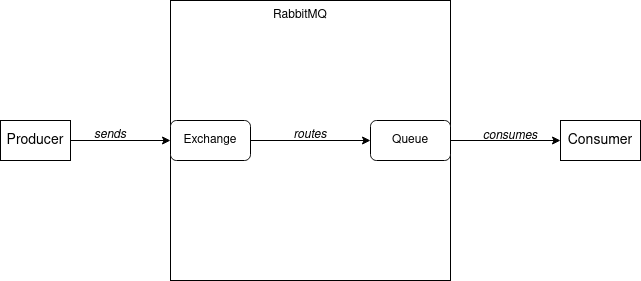
In RabbitMQ a producer publishes messages to a so-called exchange from which they are routed by the broker to one or more queues. In the example depicted the messages from the exchange are routed to a single queue. Routing messages from exchanges to queues is done according to so-called bindings which are created along with exchanges and queues by the application or administrators. Given that the bindings are configured accordingly, producers can also send a routing key along with the message to change the routing of a message.
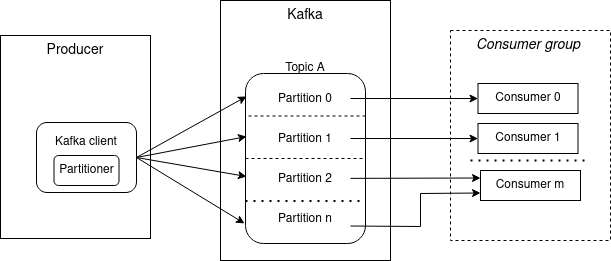
In Kafka, producer and consumer applications communicate via a so-called topic. A topic is split into multiple partitions and a message will be stored on a partition of the topic.
The component that decides the partition of a message is called partitioner and it is configured in the producer. There are pre-defined partition strategies (like round-robin or key-based partitioner) but an application can use its own partitioner.
On the consumer side, an application is typically represented by a consumer group. Technically all consumers of the same
application are configured with the same group.id. Also notice that every partition is consumed by exactly one
consumer. In the depicted example Partition 0 and 1 are consumed by Consumer 0 and 1 respectively,
but Partition 2 and n are both consumed by Consumer m.
Also how partitions are assigned to consumers inside a group is decided by so-called PartitionAssignors.
A careful reader noticed that if you have more consumers than partitions, some consumers will idle. Thus you need to increase the number of partitions to achieve scalability.
Also, there are no ordering guarantees between partitions. Imagine you stop all consumers in a group and start them
after 1 hour. If Partition 0 has only 1-hour old messages and Partition n only very recent messages, they will be
consumed in parallel despite of the message timestamp. Notice that Kafka doesn’t use the term of queue, probably
because of general lack of message ordering on topic level.
Message structure
In RabbitMQ a message has the following structure
Attributes | Payload. Only very few attributes have a meaning for the broker
like delivery mode, message priority, and expiration period. The producer can set them to implement specific features, but
in the typical scenario, no attributes are set.
Messages in Kafka on the other side have the structure
Headers | Key | Value | Timestamp. Field Value is the application payload and the optional Headers has no
special meaning to Kafka broker. The other two fields Key and Timestamp, although optional, are important to
Kafka and a developer should be aware of them. The Key field plays an important role in message order
on the consumer side and the scalability. Thus many times producers do set this field.
Multiple applications consuming same data
There are also differences between the two brokers if more applications want to consume the same data. In RabbitMQ
every application gets its own queue and the messages are routed from the single exchange to those queues. In Kafka it
is a little easier: all consumers inside the same application use a distinct group.id.